Subscribe
Alert Me when new Data Products are available


↓ Features
↓ Variables
↓ Geography
↓ Methodology
CensusCD 1990 Long Form in 2000 Boundaries allows users to access US Census data from 1990 and easily compare it with the 2000 Census data. It is the finest source of Census data from 1990 expressed at all of the 2000 geographies. The CensusCD 1990 Long Form in 2000 Boundaries is based upon the long form (STF 3) questions answered by one in six households in the 1990 census. It includes detailed demographic data about topics such as population, household structure, income, poverty, education level, employment, housing costs, immigration, and other variables. The 1990 Long Form in 2000 Boundaries is an invaluable resource for policy makers, community organizations, and researchers who want to analyze the changes that have occurred in the U.S. from 1990 to 2000.
Geographic boundaries change from census to census based on many factors. In the example below Pima County, Arizona is shown broken-out at the census tract level. At a glance, one can observe that there are changes in the census tracts from 1990 to 2000. In fact, Pima County split tracts into multiple parts, with the overall number of tracts growing from 115 to 198 tracts.
| 1990 Pima County, AZ Total Census Tracts (115) 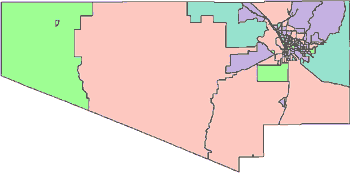 |
2000 Pima County, AZ Total Census Tracts (198) 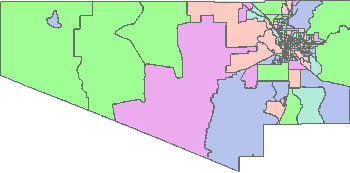 |
Taking a closer look at Pima County from 1990 to 2000 reveals the modifications in tract boundaries that significantly impact how researchers study and account for changes in a population over time. For example, below is a single 1990 Tract # 004800 that was broken into 3 tracts in the 2000 Census. It is a straight forward 1 to 3 correspondence.
| PIMA COUNTY, ARIZONA | |
1990 Tract ID# 004800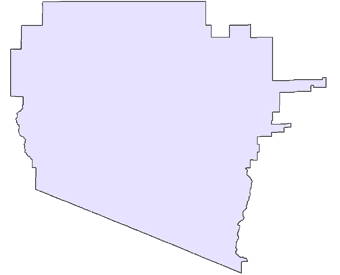 |
2000 Census Tract Boundaries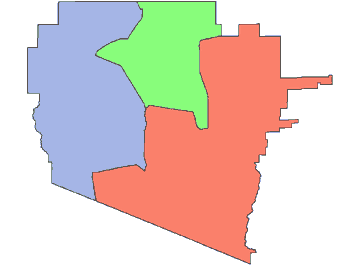 |
However, the changing tract boundaries from 1990 to 2000 are not always that straight forward. In the next example from Pima County, there are two tracts, # 004024 & # 004028, which change into 7 new tracts in 2000. The correspondence in this case is 2 to 7. From these two examples in Pima County, it becomes evident why it is so difficult for researchers to contend with the issue of changing geographic boundaries over time.
1990 Tract ID# 004024 & 004028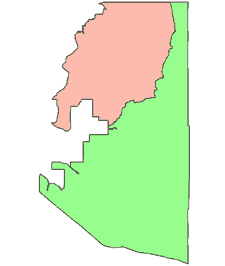 |
2000 Census Tract Boundaries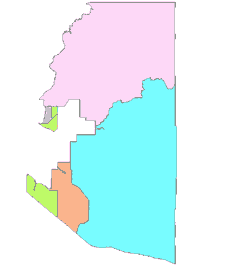 |
Normalizing the Data
The actual re-mapping procedure for converting data from 1990 to 2000 boundaries is quite complicated. Here is a link for those wishing a more technical explanation of this task (click here). The basic procedure was to use the Tiger/Line 2000 relationship between 2000 blocks with those from 1990. This allowed us to identify how block boundaries had changed between censuses. For example, if a 1990 block split into two for the 2000 census, others tracts merged, while some tracts both merged and then split. The table below shows the three scenarios (many to one, one to many, and many to many).
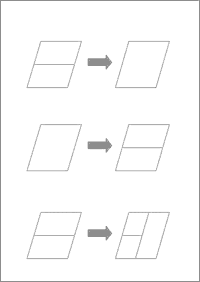
There are 8.2 million blocks in the US in 2000, so in fact these are very small geographic areas. But in order to be more precise, when necessary we broke blocks down. When the blocks split then the matter of how to split the population becomes a problem. (When they merge you just add the numbers). In order to determine how to subdivide blocks we looked at the Tiger Street files. The assumption being that people live on or near streets, so the number of addresses on a street will indicate the approximate weight to give to that area of the block.
From the blocks or block parts we created a Block Weighting File. These population weights were then applied to the various other counts to convert them to 2000 block boundaries. Once the data had been calculated at the block level we were then able to sum up the blocks to the various other geographies. Testing was then done to assure the accuracy and validity of the weighting method compared with the original numbers from the 1990 Long Form data set.
| Basic | |
|---|---|
| State User | $449.00 |
| National User | $895.00 |
| STF3A Demographic Data | ✪ 3770 variables |
Over 3,500 demographic variables are available for every area. Whether you need to know the total population, median income, housing values, or even the percent of houses with indoor plumbing in a given area, CensusCD 1990 Long Form can provide your answers. It contains all of the demographic variables released on the 1990 Census STF-3 files.
CensusCD 1990 Long Form in 2000 Boundaries covers over 375,000 locations (zips, block groups, tracts, counties, etc). The Census Bureau organizes the variables into 300 different Tables. To aid with selection, we categorized the tables into the following 14 groups:
General - summaries of demographic characteristics
Header - Geographic Identifiers, details of geographic definitions
Person - population variables by age and gender
Families - characteristics of family units
Household - descriptions of family and non-family living
Race - racial data by age and gender
Language - first and second languages and English proficiency by ages
Occupation - profession, employment, and commuting times
Education - educational enrollment and attainment levels by age and gender
Income - income source and amounts by household, family, per capita also broken out by age and race
Poverty - levels of poverty by household, age and race
Housing - size, value, plumbing and kitchen facilities, heating fuels
Rent Housing - rental amounts and characteristics
Owner Occupied - owner characteristics, mortgage amounts, and housing values
For a complete list of 1990 Long Form variables, Click Here.
12 geographies covering over 360,000 locations
CensusCD gives you over 3,500 demographic variables for 360,000 geographic areas of the United States. These geograhic areas consist of the following levels (numbers indicate how many specific geographies within that level):
United States (1)
States (51)
PMSA (76)
MSA/CMSA (280)
106th Congessional District (436)
American Indian Reservations (651)
Counties (3,141)
Census Designated Places (25,150)
MCD (35,164)
Zip Codes (ZCTA) (32,232)
Census Tracts (65,232)
Block Groups (208,790)
Note the following acronyms:
PMSA = Primary Metropolitan Statistical Area
MSA = Metropolitan Statistical Area
CMSA = Consolidated Metropolitan Statistical Area
MCD = Minor Civil Division
How have characteristics of population and housing changed in the United States over time? What information is available to support this analysis? The Long Form released by the US Census Bureau contains the most detailed set of official US demographics available. In 1990 this set of data is referred to as Summary Tape File 3 (STF3) and in 2000 it is called the Summary File 3 (SF3). There are several issues that arise when you try to compare two sets of data that were collected ten years apart. Direct comparisons between these two sets of data are made more complicated by two factors: 1. changes in the questionnaire design and 2. changes in area boundary definitions.
The first issue, changes in the questionnaire design, has several components: wording of questions that vary, ordering of the questions, categories of questions are dropped and others added. There are also instances of cross-tabulation tables changing, as well as many cross-tabulations that were released in 1990 at the Block Group but only released at the Tract level in 2000. Furthermore, sometimes data for small areas like block groups and tracts were imputed, or taken from like or nearby areas, to protect confidentiality. This also decreases the reliability of the data at smaller levels of geography. Likewise, population under-counting and over-counting may be addressed differently in different census years. These types of issues may be addressed by reviewing the summary information provided by the US Census.
The second obstacle is the changes in geographic definitions. These occur because areas split (1:2), merge (2:1) or both (2:3). The remainder of this paper will discuss how GeoLytics normalized the 1990 Long Form census data to various 2000 geographies. This enables comparisons between 1990 and 2000 Long Form data to be made in standard 2000 geographies. To explain the normalization of 1990 STF3 data to 2000 geographies, we start by weighting and converting 1990 Block Group data to 2000 areas. 1990 Block Group data is used because it is the smallest level of 1990 geography at which the full set of US Census 1990 Long Form data is available. To facilitate the splitting and merging of 1990 Block Groups to 2000 areas, Census Blocks are used. A Census Block is much smaller than a Block Group. There are approximately 30 to 40 Blocks in each Block Group. And unlike previous censuses, Blocks and Block Groups cover 100% of the US in 1990 and 2000.
The 1990 to 2000 Block relations were determined from Tiger/Line 2000, Type 1 and Type 3 records. 85% of the Blocks had a 1:1 relationship, 10% had a 2:1, and 5% had a greater than 2:1. Block splits between 1990 and 2000 were weighted by an analysis of the 1990 streets. To split a Block into parts, the sub-Block areas were weighted according to the 1990 streets relating to each 2000 Block part. The assumption is that local roads indicate where the population lived. 1990 streets were determined using Tiger/Line 1992. Using Tiger 1992 and Tiger 2000 we created a correspondence between 1990 and 2000 Blocks, as well as a weighting value. The weighting value was then used to help split Block demographics for those Blocks that had been split or merged between 1990 and 2000. The file produced by this process is the 1990 to 2000 Block Weighting File (BWF). From this BWF we can roll up the 1990 data to any 2000 geography (tract, zip code, county, etc.).
A final weighting consideration should be noted. The weighting of 1990 Block Group data to 2000 areas has been done as statistically accurately as possible. The 1990 STF3 data is the official Census data and our methodology presents an accurate and comprehensive method to statistically compare 1990 data with 2000 data. However, the converted 1990 data in 2000 boundaries cannot be considered official census data. While a major obstacle to comparing altered geographic areas has been overcome, those areas that have not changed between 1990 and 2000 may contain rounding differences in the weighting process and may not exactly match the official census.